【徹底解説】GPUサーバーを増やすだけでは速くならない?
AI・LLM向けHPCクラスタ構築で押さえておきたいポイント
生成AIや大規模言語モデル(LLM)の開発では、モデル規模や学習データ量の増加に伴い、単体のGPUワークステーションやGPUサーバーだけでは、必要な処理性能を確保できないケースが増えています。
そこで選択肢となるのが、複数のGPUサーバーを連携させたHPCクラスタです。
ただし、GPUサーバーを複数台導入すれば、台数に比例して処理性能が向上するとは限りません。ノード間ネットワーク、ストレージ、ソフトウェア環境、リソース管理などに問題があると、GPUが本来持つ性能を十分に活用できない場合があります。
本記事では、AI・LLM開発向けHPCクラスタで発生しやすいボトルネックと、構成を検討する際に確認しておきたいポイントを、実際のご相談で確認する内容も交えながら解説します。

GPUサーバーを増やしても性能が伸びない理由
複数ノードを利用した分散学習では、GPU間でモデルのパラメータや計算結果を頻繁にやり取りします。
GPU単体の演算性能が高くても、サーバー間の通信やストレージからのデータ供給が追いつかなければ、GPUに待ち時間が発生します。その結果、GPUノードを増設しても、想定したほど処理時間を短縮できないことがあります。
実際のご相談では、GPUサーバー本体の仕様は決まっているものの、以下の条件が未確定というケースも少なくありません。
・GPUサーバー間を接続するネットワークの仕様
・学習データを保存する共有ストレージの構成
・複数ユーザーでGPUを共用する方法
・設置先のラック、電源容量、空調条件
・導入するOSやCUDAなどのソフトウェア環境
・将来的なGPUノードの増設計画
HPCクラスタは、サーバー単体ではなく、これらを一つのシステムとして設計することが重要です。
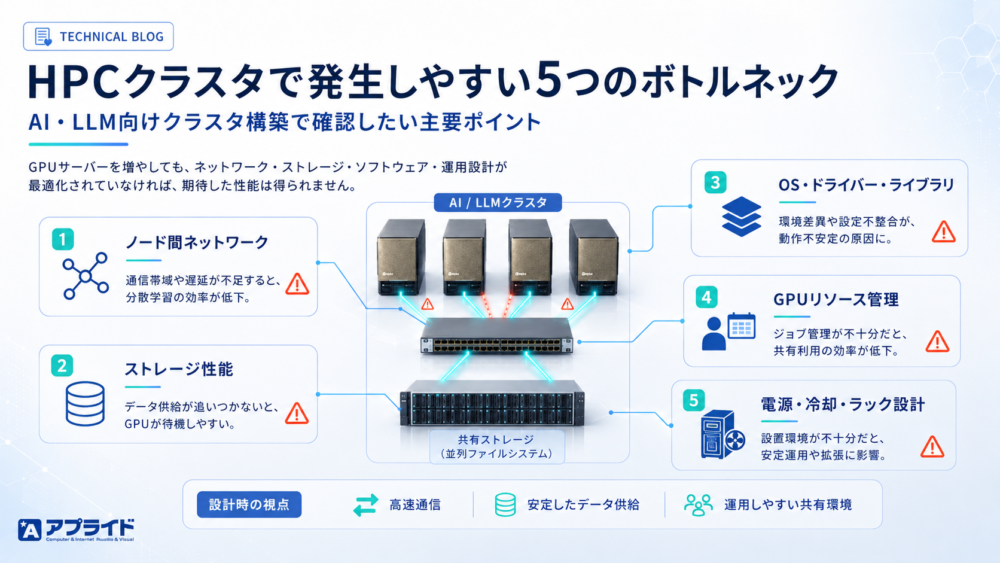
図:AI・LLM向けHPCクラスタで発生しやすい5つのボトルネックを示した図
HPCクラスタで確認したい5つのボトルネック
1.ノード間ネットワーク
分散学習では、GPUサーバー間で大量のデータを転送します。
ネットワークの帯域が不足していたり、通信遅延が大きかったりすると、GPUが他のノードからのデータを待つ時間が増えます。用途やノード数に応じて、InfiniBandや100GbE・200GbEなどの高速ネットワークを検討する必要があります。
導入後は、単に通信できることを確認するだけでなく、NCCL通信テストなどを通じて、想定した帯域やGPU間通信性能が得られているかを確認することが重要です。
2.ストレージからのデータ供給
AI学習では、画像、動画、テキスト、シミュレーション結果など、大量のデータを繰り返し読み込みます。
ストレージ性能が不足すると、GPUへのデータ供給が間に合わず、GPU使用率が上がりません。複数ノードから同時にデータへアクセスする場合は、データ量やアクセス特性に応じて、NFS共有ストレージのほか、BeeGFSやLustreなどの並列ファイルシステムも選択肢となります。
ただし、すべての環境に並列ファイルシステムが必要とは限りません。データ容量、ファイル数、同時アクセス数、予算などを確認し、必要以上に複雑な構成にしないことも大切です。
3.OS・ドライバー・ライブラリ
クラスタ内でOS、NVIDIA Driver、CUDA、NCCL、MPIなどのバージョンが統一されていないと、ノードごとの動作差や通信エラーにつながる可能性があります。
DockerやApptainerなどのコンテナ環境も含め、各ノードで再現性のあるソフトウェア環境を整えることで、環境差によるトラブルを抑えやすくなります。
4.GPUリソースの管理
複数部門や複数ユーザーがGPUクラスタを共用する場合、手作業や先着順での管理では、GPUの占有、ジョブの競合、空きリソースの未活用が発生しやすくなります。
Slurmなどのジョブスケジューラを利用することで、GPU、CPU、メモリなどの計算資源をジョブごとに割り当て、クラスタ全体を効率的に利用できます。
5.電源・冷却・ラック設計
高性能GPUを複数搭載したサーバーは、一般的なサーバーと比較して消費電力と発熱量が大きくなります。
構成決定後に設置条件を確認すると、電源工事やラック変更が必要になることもあります。導入前に、電源容量、電源系統、コンセント形状、ラックの奥行き、搭載重量、空調、排熱方向などを確認しておく必要があります。
また、将来的なノード追加を予定している場合は、ラックスペースやスイッチポート、電源容量にも余裕を持たせることが重要です。
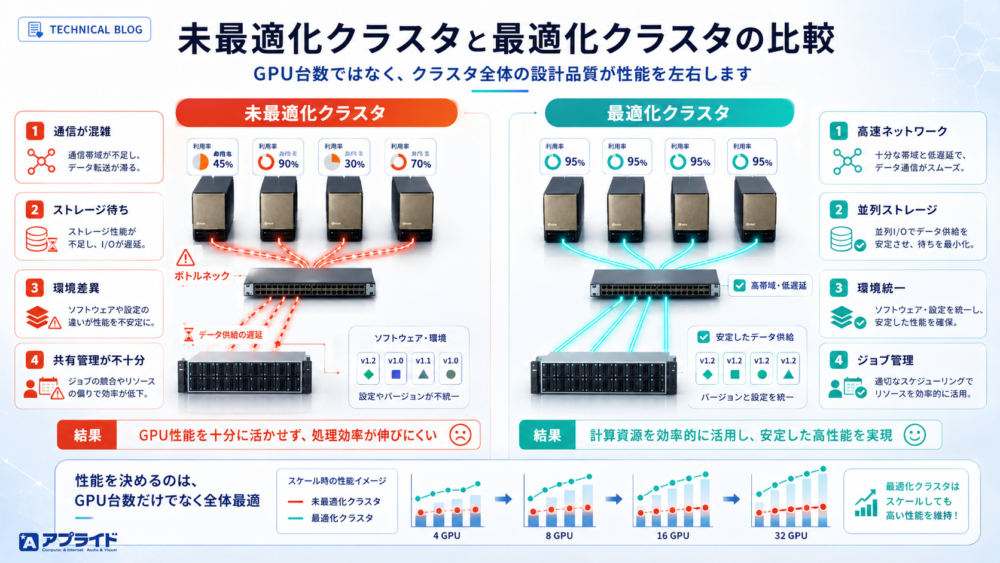
図:未最適化クラスタと全体設計された最適化クラスタの比較図
すべてのAI開発にHPCクラスタが必要なわけではない
大規模なHPCクラスタは高い処理性能を実現できますが、すべてのAI開発に必要なわけではありません。
モデルの検証や小規模な推論、少人数での開発であれば、単体のGPUワークステーションで十分な場合があります。一方で、次のような場合は、複数GPUサーバーやHPCクラスタの検討が有効です。
・単体サーバーではGPUメモリや計算性能が不足する
・複数ノードを利用した分散学習を行いたい
・複数部門や複数ユーザーでGPUを共同利用したい
・大量の学習データを複数ノードへ高速に供給したい
・AI学習とHPCシミュレーションを同じ基盤で運用したい
・将来的にGPUノードを段階的に増設したい
重要なのは、最初から大規模なクラスタを導入することではありません。現在の開発規模と、数年後に想定されるモデル規模、データ量、利用人数を踏まえて、段階的に拡張できる構成を検討することが重要です。
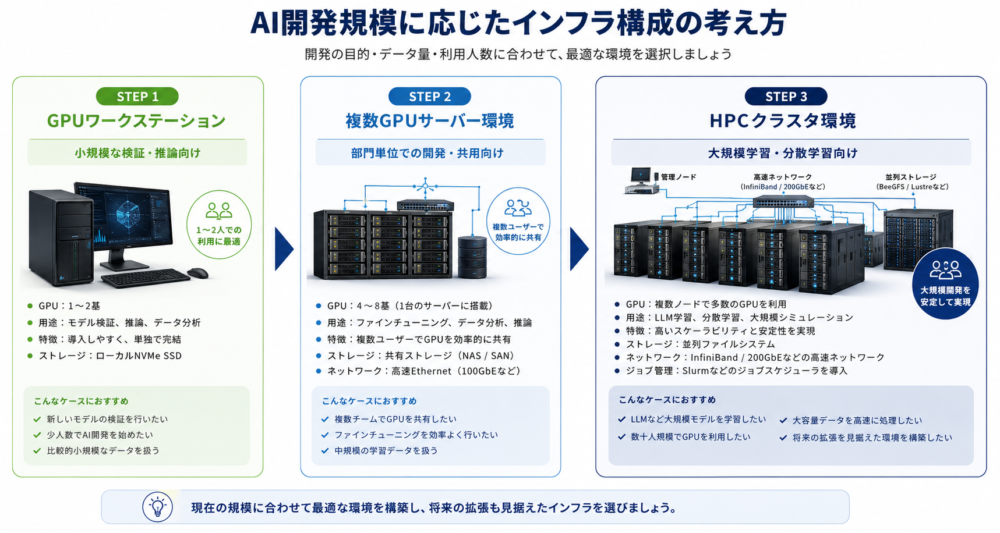
図:GPUワークステーションからHPCクラスタまでのAI開発規模別構成図
アプライドが構成検討時に確認するポイント
AI・LLM向けHPCクラスタの構成は、GPUの型番や搭載枚数だけでは決められません。
アプライドでは、お客様のご要望を確認する際に、主に次の項目を整理します。
利用目的・ワークロード
・学習、推論、ファインチューニングのどれを行うか
・使用するAIモデルやアプリケーション
・PyTorchなど、使用するフレームワーク
・分散学習の実施予定
・AI処理以外にCAEやシミュレーションを行うか
データ・計算規模
・モデルの規模
・必要なGPUメモリ容量
・学習データの容量とファイル形式
・同時に実行するジョブ数
・必要な処理時間や目標性能
利用者・運用方法
・利用人数と部門数
・複数ユーザーでGPUを共有するか
・ジョブスケジューラが必要か
・ユーザーアカウントやアクセス権限の管理方法
・運用を担当する管理者の有無
設置・拡張条件
・設置場所とラックの有無
・使用可能な電源容量
・空調・排熱条件
・既存ネットワークやストレージとの接続
・将来的なGPUノードの追加予定
これらを確認したうえで、単体のGPUワークステーション、複数GPU搭載サーバー、マルチノードHPCクラスタの中から、用途とご予算に適した構成をご提案します。
構成がまだ明確に決まっていない段階でも、使用予定のアプリケーション、データ量、利用人数などから、必要な要件を整理することが可能です。
HPCクラスタはシステム全体で設計する
AI・LLM向けHPCクラスタでは、高性能なGPUを選ぶことに加えて、GPUを効率よく動かすための周辺環境が重要です。
アプライドでは、協力パートナーと連携し、ご要件に応じて以下の内容をご提案します。
・GPUサーバー・管理ノードの選定
・ラック設置・電源配線・ケーブリング
・InfiniBand・高速Ethernetネットワーク構築
・Linux・NVIDIA Driver・CUDA環境構築
・NCCL・MPIなどの並列処理環境構築
・Slurmによるジョブ管理環境構築
・NFS・BeeGFS・Lustreなどのストレージ環境構築
・Prometheus・Grafanaなどを利用した監視環境構築
・ノード間通信・GPU通信・並列実行の動作確認
対応範囲は、システム構成やご要件によって異なります。詳細な設定内容については、協力パートナーを含めて対応可否を確認したうえでご案内します。
サービス内容や導入までの流れについては、下記ページをご覧ください。

AI・LLM開発環境についてのなお問い合わせは、下記フォームよりご連絡ください。

